Web Scraper
Introduction
Web scraping is the act of retrieving data from a third party website by downloading the HTML code representing the website and then parsing the code to extract the desired content. Since most websites do not offer an API, web scraping is a
great
alternative for aggregating valuable data.
Most data can be extracted from HTML code, making this a versatile project!
What was used
This project was made using Java 11 and the standard libraries that java comes with.
Implementation
Developing the web scraper was divided into two parts, a parser and a server communications part.
The parser was designed to take HTML code and return a general tree structure with the nodes being either element/tag-nodes or text-nodes. With the general tree class it's possible to search for specific data that is found on the website.
It should be noted that the parser ignores comments found in the HTML code since this parser is designed to only parse data that is visible on the website.

Server communications is pretty much a class for setting up a user agent as well as making sure the URL is valid before trying to send an HTTP request to retrieve the HTML code from the URL. To the fellow reader who might have never heard about
user agents,
the user agent can be seen as a sort of identification so the server can figure out from where and from what type of device and software this HTTP request is coming from.
"Mozilla/5.0 (X11; Linux x86_64; rv:75.0) Gecko/20100101 Firefox/75.0",
Mozilla/5.0 is commonly used by all browsers, (X11; Linux x86_64; rv:75.0) tells us that the call is made by a linux machine, Gecko/20100101 is the browser
engine
used and finally Firefox/75.0 says that the HTTP request is made from a firefox browser with version 75.
With this in mind we can minimize the risk that the website notices that this is a scraper and not a browser by setting up our custom user agent.
To display the capabilities of the web scraper a demo was setup utilizing a local database using text files for storing and accessing data. I want to point out that I was meant to use a remote mySQL database but due to time constraints I had to use this quick solution. In the local database I attempt to simulate a portfolio of stocks where the current price of each stock is fetched using the web scraper.
Demonstration
As previously mentioned a local database was made to simulate a portfolio of stocks. The data that is currently stored is the ticker name of the stock, number of shares that are owned and finally the URL where the price of the stock can be
found.
The following image shows the representation of the data, "name-of-stock(ticker):URL|".

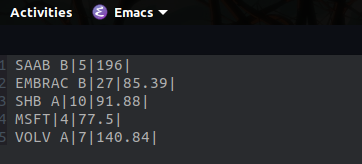
The following image shows the contents of the portfolio, "ticker-of-the-stock|number-of-shares|buy-in-price|".
Prices are in SEK, with the total portfolio being evaluated at 5500.21 SEK.
The demo itself is fairly straight forward, the program will fetch the data from the portfolio and then match the tickers for each company with their respective url. After a match has been made, the web scraper will use the url to look up the
current price of the stock. This will be done for every company in the portfolio, once this process is complete the current value of the portfolio will be calculated and returned to the user, see the image below.
The following run was done at 16:48 on August the 17th 2020.
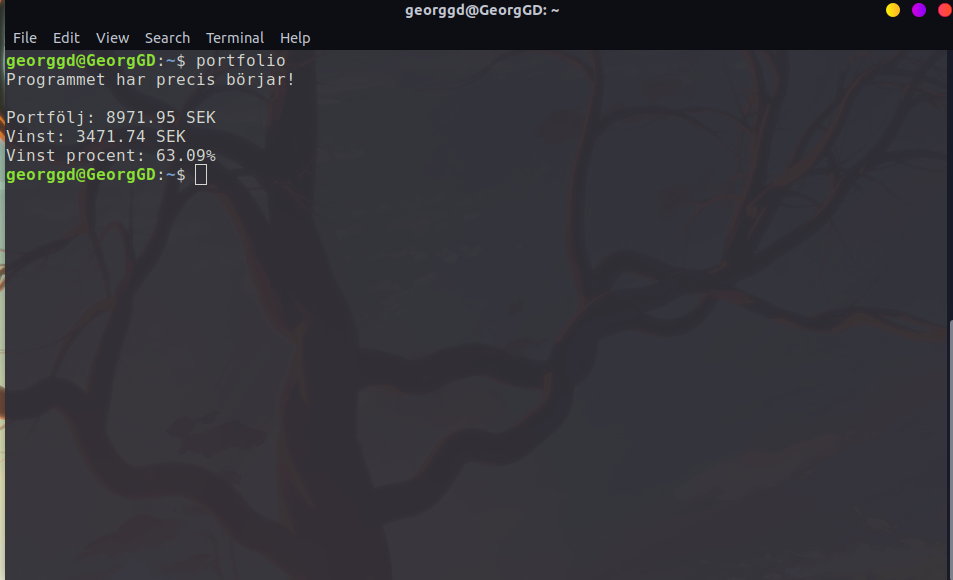
The english translation of what you see in the image is:
The program has just started!
Portfolio: 8971.91 SEK
Profit: 3471.74 SEK
Profit margin: 63.09%
Improvements
For starters in this project there was very little effort devoted to exception handling which I would like to improve and to make sure I put more emphasis into my future projects.
Something else I would like to improve upon is my representation of attribute values in my ElementNode-class.
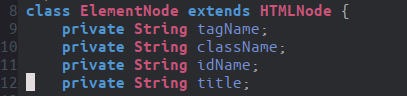 As you can see, this is messy and not managaeble. Instead what I should have done is to store the name of the tag just like I am doing but to store all the attribute values inside a map structure. For example, a
hash table would have worked great here since I can simply store the name of the attribute as a key and the value inside the attribute as a value to pair our key. This would allow the parser to store all attributes and their
respective values. It would also simplify searching for nodes with specific key and value pairs.
As you can see, this is messy and not managaeble. Instead what I should have done is to store the name of the tag just like I am doing but to store all the attribute values inside a map structure. For example, a
hash table would have worked great here since I can simply store the name of the attribute as a key and the value inside the attribute as a value to pair our key. This would allow the parser to store all attributes and their
respective values. It would also simplify searching for nodes with specific key and value pairs.
One major drawback to this solution is that it would slow down the parser since we would have to store ALL attributes inside every tag.
While we are on the topic of map structures, one more improvement that I could make is to introduce a map structure that stores attributes who normally hold unique values, such as the id attribute. This map could be stored as a
private variable and with the value of the unique identifier as the key and the pointer to the element node as the value. This solution would improve the time it takes to search for an element but it would once again slow down the performance
of the parser.
Conclution
To conclude this article, I would like to emphasize that this project isn't 100% complete and that there still is room for improvement. I would also like to point out that I'm currently not planning to make the repository public
since I use the demo for tracking my own stock portfolio (the example that I used wasn't my portfolio) and therefore I don't want that information in the public domain. The only time I would be comfortable letting someone else
look into the repo is for a job interview.
With that said, this project could use a bit more optimization as it seems to run slowly when parsing multiple URL's. Otherwise the resulting program is quite satisfying especially since it's useful to track my own stocks and with a few
tweaks
and with the implementation of a remote server it would be possible to turn this into a SaaS program.
The only thing holding this project back are the looming university exams that I need to devote more time to.
Written on the 2020-08-17