Website Integrated WebScraper
Introduction
The following project is my attempt to implement what I have learned about the Spring Framework and the Selenium Framework to create a website that scraps other websites and displays the
content that was scraped. The purpose of this website is to demonstrate web scraping but to also give myself the opportunity to build a web application.
Don't forget to checkout the repository for this project on Github.
What was used
This project was made using Java 11, JUnit, Maven, Selenium and the Spring Framework.
Implementation
Development of this project was divided into two sections, the backend that consists of the web scraper and the web application that connects the backend with the frontend.
The backend consists of an interface named DriverManager whose purpose is to allow the user to use any sort of framework or package to do web scraping. The interface itself makes the whole project a little bit
more moduler
which is great since there is a plan to use my previous web scraper project in the future.
While we are in the topic of the DriverManager-class, let's quickly talk about the class that is implementing it, the SeleniumDriver-class. The class is design to allow the user to use the browser they prefer by
simply providing the
driver to
SeleniumDriver. From their SeleniumDriver handler everything from navigating to the given url to then scrap the content the user wishes to scrape.
Finally we have the WebScraper-class whose purpose is add a layer of abstraction so that the user of the backend only needs to focus on managing this class without knowing which DriverManager is being used or how the
web scraper collects the desired data.
For the web application itself I ended up using Spring MVC combined with xml-configuration for setting up the servlet such that HTTP calls to specific controllers would be mapped from the web.xml. The controller used by the web application, WebScraperController, is responsible for collecting data from the frontend, providing it to the WebScraper-class to scrape content from a
website and finally provide the scraped content to the frontend user.
Demonstration
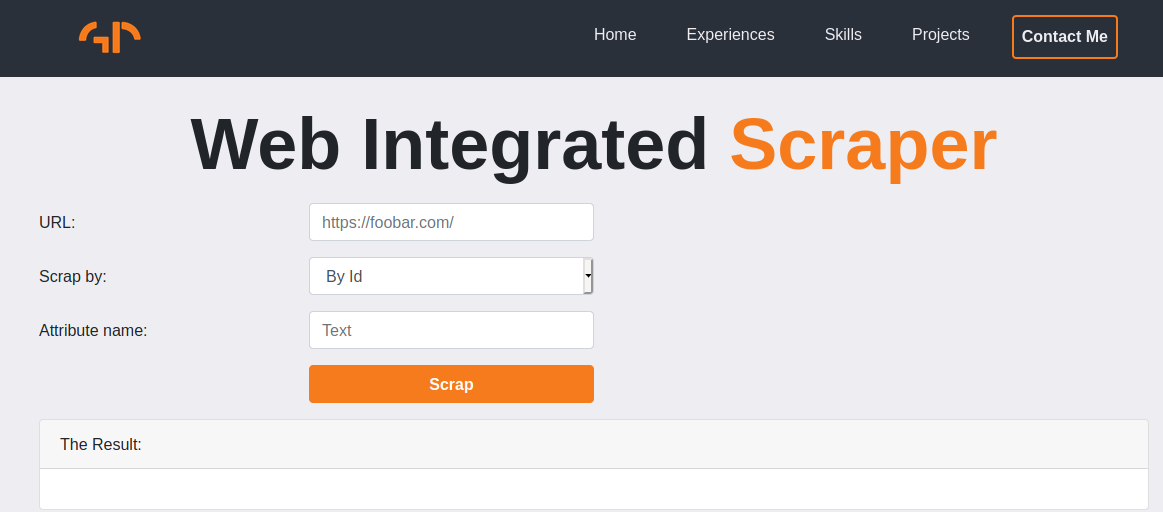
Please download the repository on Github and follow the instructions for running the demo. You should be greeted by a page like in the figure below. I would
highly recommend using the xpath,name or the id option as these tend to be unique and will lead to your desired content being scraped.
Improvements
After finally completing the important parts of this project there ended up being a few things I would have liked to improve upon. For starters my program doesn't take into account that some website do have pop ups and this could lead to errors
that as of
now are not being handled. On top of that I'm not handling the case when the user selects a class name shared by multiple tags and so I don't know what the outcome would be but I do believe it should lead into an error.
One more area that I would like to improve on is documenting my code, more precisely writing good documentation.
Finally I would like to write a couple of more unit tests (and integration tests) since if I compare this project with my previous one I do feel as if I'm lacking in the number of unit tests.
Conclution
In conclusion my very first spring project ended up being a massive success. I have managed to create a working web application that easily and effectively demonstrates web scraping. I would also like to point out how a webapp project seemed
incredibly difficult for me 6 months ago so this project does make me feel like I have progressed quite a bit as a developer.
Hopefully for my new webapp project I can create something a bit more complicated.
Written on the 2020-11-04